Deposition Date
2017-09-14
Release Date
2018-09-19
Last Version Date
2023-10-04
Entry Detail
Biological Source:
Source Organism(s):
Escherichia coli O157:H7 (Taxon ID: 83334)
Expression System(s):
Method Details:
Experimental Method:
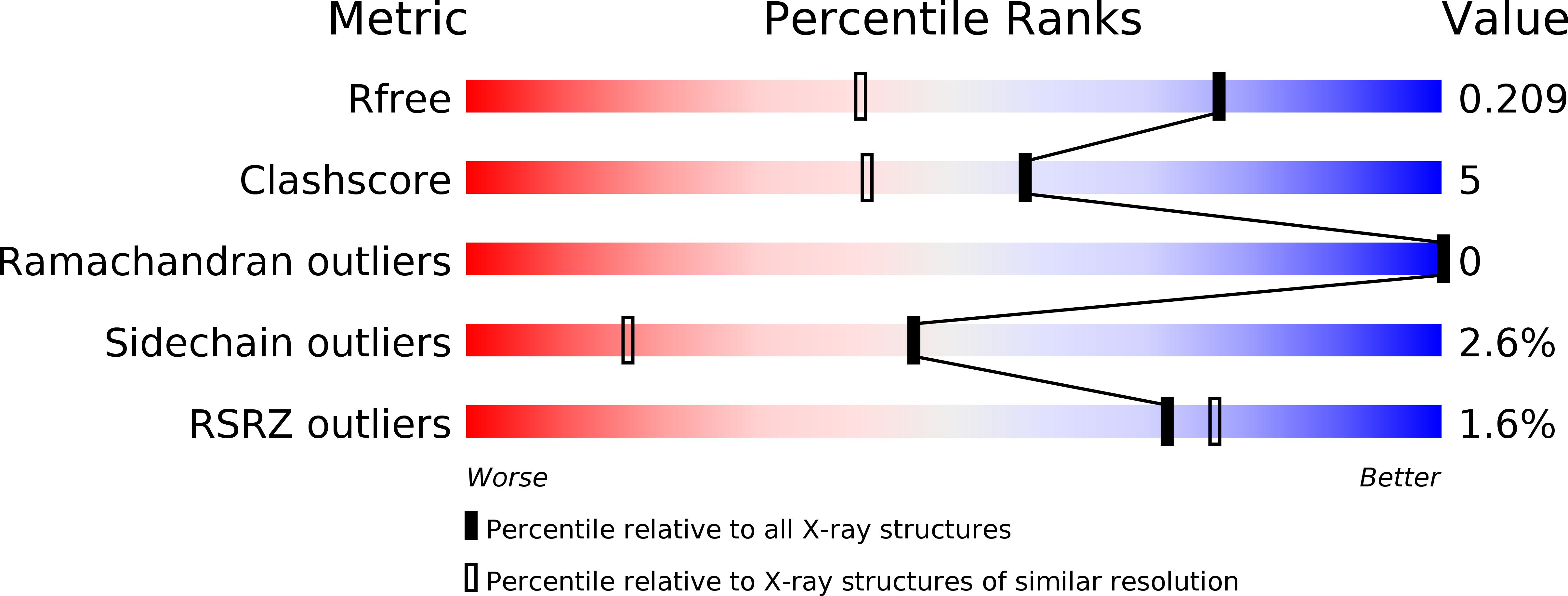
Resolution:
1.50 Å
R-Value Free:
0.20
R-Value Work:
0.17
R-Value Observed:
0.17
Space Group:
C 2 2 21